KNIME ANALYTICS PLATFORM - przygotowanie danych do analizy - operacje na wierszach i węzłach
W niniejszej, czwartej części cyklu na temat platformy analitycznej KNIME kontynuujemy temat przygotowania danych do analizy. We wcześniejszym numerze przedstawiliśmy najczęściej używane węzły do wykonywania przekształceń w kolumnach, tj. grupowanie, konwersja, zamiana wartości, filtrowanie, dzielenie, łączenie oraz transformowanie danych. Tym razem zbadamy zakres dostępnych operatorów (węzłów) z kategorii manipulowania danymi w wymiarach reprezentujących wiersze i całe tabele.







Ponadto można śmiało stwierdzić, że na tym etapie poznajemy istotny obszar pracy analityka czy badacza danych, jakim są czynności kryjące się pod pojęciami ETL, preprocessing, data blending. Niewątpliwie warto solidnie zaznajomić się z możliwościami KNIME w tym obszarze, ponieważ pozwoli to znacząco przyspieszyć i zautomatyzować cały proces analizy danych. Co więcej, zignorowanie tego etapu może skutkować błędnymi wynikami analiz lub całkowicie uniemożliwić ich przeprowadzenie. Poza tym zdobyta wiedza z pewnością przyda się w kolejnej, bardziej praktycznej części cyklu, w ramach której zaprojektujemy pierwszy workflow oraz wykonamy proste analizy statystyczne.
Przejdźmy zatem do poznania zawartości repozytorium w kategorii Manipulation – Row, Table.
Filter – filtrowanie danych
Nominal Value Row Filter
Filtruje wiersze według wybranej wartości atrybutu nominalnego. Możemy wybrać kolumnę nominalną i jedną lub więcej wartości nominalnych tego atrybutu. Wiersze o tej wartości nominalnej w wybranej kolumnie są zawarte w danych wyjściowych.
Nominal Value Row Splitter
Dzieli wiersze na podstawie wybranej wartości atrybutu nominalnego. Również wybieramy kolumnę nominalną i jedną lub więcej wartości nominalnych tego atrybutu. Wiersze o tej wartości nominalnej w wybranej kolumnie są zawarte w pierwszym porcie danych wyjściowych, natomiast pozostałe wiersze w drugim porcie danych wyjściowych.
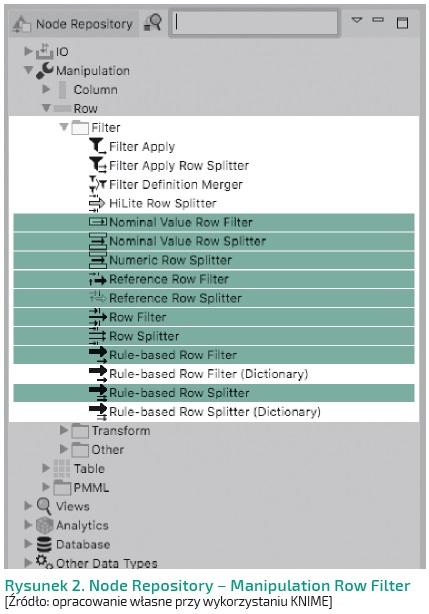
Numeric Row Splitter
W oknie dialogowym węzła wybieramy kolumnę liczbową oraz ustawiamy zakres liczbowy, aby podzielić dane na dwie części. Pierwszy port wyjściowy zawiera dane spełniające kryteria, drugi zawiera pozostałe dane.
Reference Row Filter
Węzeł umożliwia filtrowanie wierszy z pierwszej tabeli za pomocą wierszy zawartych w drugiej tabeli. W zależności od ustawień wiersze z drugiej tabeli są włączane lub wyłączane w tabeli wyjściowej.
Reference Row Splitter
Węzeł umożliwia dzielenie wierszy z pierwszej tabeli przy użyciu wierszy zawartych w drugiej tabeli. Wiersze wspólne z obu tabel dostępne są w pierwszym porcie wyjściowym, a reszta w drugim porcie.
Row Filter
Węzeł umożliwia filtrowanie wierszy w tabeli według różnych kryteriów.
Wiersze mogą być wykluczane lub dołączane na podstawie dopasowania do określonych wartości, wyrażeń regularnych, zakresu wartości, numerów wierszy czy też poprzez wzorzec ID wierszy. Możliwe jest definiowanie wzorców dopasowania wartości przy użyciu symboli wieloznacznych, tj. „*” – wartości pasujące do dowolnej sekwencji – i „?” – wartości pasujące do jednego znaku.
Row Splitter
Węzeł ma dokładnie tę samą funkcjonalność co węzeł Row Filter, ale ma dodatkowy port wyjściowy, który zawiera odfiltrowane wiersze, niespełniające kryteriów filtrowania.

Rule-based Row Filter
Węzeł ma możliwość definiowania reguł logicznych sprawdzających wartości w wierszach.
W zależności od wyniku (TRUE/FALSE) wiersze mogą zostać dołączone lub wykluczone z tabeli wyjściowej.
Rule-based Row Splitter
Węzeł umożliwia definiowanie reguł logicznych w ten sam sposób co Rule-based Row Filter, ale ma dodatkowy port wyjściowy, który zawiera odfiltrowane wiersze, niespełniające kryteriów filtrowania.
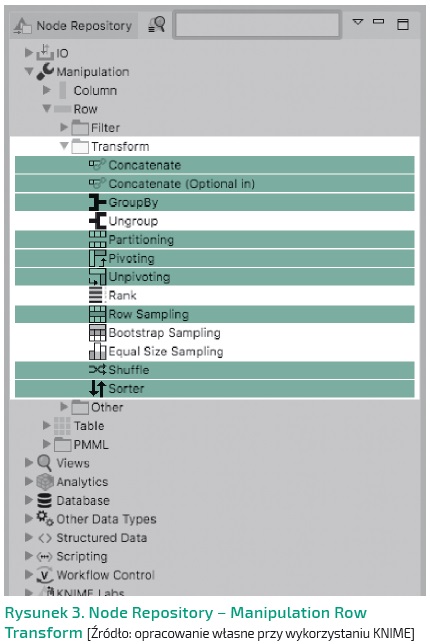
Transform – transformowanie danych
Concatenate
Węzeł łączy
dwie tabele.
Dołączane są wartości kolumn o identycznych nazwach. Jeśli jedna tabela wejściowa zawiera nazwy kolumn, których nie ma inna tabela, kolumny mogą być wypełnione brakującymi wartościami lub są odfiltrowane, tzn. nie są zawarte w tabeli wyjściowej.
Concatenate (Optional in)
Węzeł umożliwia połączenie do czterech tabel w identyczny sposób co węzeł Concatenate.
GroupBy
Grupuje wiersze tabeli według unikatowych wartości w wybranych kolumnach grupy. Dla każdego unikatowego zestawu wartości wybranej kolumny grupowej tworzony jest wiersz. Pozostałe kolumny są agregowane zgodnie z określonymi ustawieniami agregacji. Tabela wyjściowa zawiera jeden wiersz dla każdej unikatowej kombinacji wartości wybranych kolumn grupy. Kolumny do agregacji mogą być zdefiniowane przez wybranie kolumn bezpośrednio, według nazwy na podstawie wzorca wyszukiwania lub na podstawie typu danych. Do dyspozycji mamy wiele metod agregacji danych w zależności od typu zmiennej, są to m.in.: suma, średnia, mediana, liczba wystąpień, minimum, maximum, pierwsza lub ostatnia wartość, lista.
Partitioning
Węzeł dzieli dane na dwie partycje według zdefiniowanych ustawień, tj. wielkości oraz sposobu dobierania wierszy do pierwszej partycji. Pozostałe wiersze dostępne są w drugim porcie wyjściowym.
Pivoting
Węzeł umożliwia „obracanie” i agregowanie wartości tabeli wejściowej przy użyciu wybranych kolumn oraz metod agregacji danych identycznych jak w węźle GroupBy. Trzy porty wyjściowe zawierają tabelę przestawną oraz podsumowania grupowanych wartości.
Unpivoting
Węzeł „obraca” i zamienia wybrane kolumny z tabeli wejściowej w wiersze, jednocześnie duplikuje pozostałe kolumny wejściowe, dołączając je do każdego odpowiedniego wiersza wyjściowego.
Row Sampling
Węzeł umożliwia wyodrębnienie próbki danych z tabeli wejściowej. Opcje konfiguracji są identyczne jak w węźle Partitioning, ale otrzymujemy jeden port wyjściowy z próbką danych.
Shuffle
Węzeł przesuwa wiersze względem siebie tak, aby w tabeli wyjściowej były w kolejności losowej.
Sorter
Węzeł sortuje wiersze. W ustawieniach wybieramy kolumny oraz sposób sortowania danych.
Other – inne przekształcenia danych
Extract Column Header
Tworzy nową tabelę z jednym wierszem zawierającym nazwy kolumn tabeli wejściowej oraz w drugim porcie wyjściowym zawiera dane wejściowe, przy czym nazwy kolumn mogą zostać zmienione według ustawionego wzorca w konfiguracji węzła.
Insert Column Header
Aktualizuje nazwy kolumn tabeli według zawartości drugiej tabeli słownikowej.
RowID
Węzeł umożliwia zastąpienie lub stworzenie nowej kolumny zawierającej unikatowe ID wiersza.
Rule Engine
Węzeł umożliwia definiowanie reguł logicznych sprawdzających wartości w wierszach. Jeśli wyrażenie jest zgodne (TRUE), to wartość zdefiniowanego wyniku może zostać dodana do nowej kolumny w tabeli lub może zastąpić wartości wybranej kolumny.
Table – operacje na tabeli
Extract Table Dimension
Węzeł wyodrębnia i zapisuje w tabeli wyjściowej liczbę wierszy i kolumn tabeli wejściowej. Pierwszy wiersz zawiera liczbę wierszy, a drugi liczbę kolumn.
Extract Table Spec
Węzeł wyodrębniający informacje meta z tabeli wejściowej, tj. nazwy kolumn, typy, indeks oraz dolne i górne granice wartości w kolumnach. Każda kolumna w tabeli wejściowej jest reprezentowana jako wiersz w produkcie.
Transpose
Przestawia tabelę wejściową,
zamieniając wiersze i kolumny.
Nowe nazwy kolumn pochodzą z wcześniejszych nazw wierszy i odwrotnie.











